
We propose a semantic-aware neural reconstruction method to generate 3D high-fidelity models from sparse images. To tackle the challenge of severe radiance ambiguity caused by mismatched features in sparse input, we enrich neural implicit representations by adding patch-based semantic logits that are optimized together with the signed distance field and the radiance field. A novel regularization based on the geometric primitive masks is introduced to mitigate shape ambiguity. The performance of our approach has been verified in experimental evaluation. The average chamfer distances of our reconstruction on the DTU dataset can be reduced by 44% for SparseNeuS and 20% for VolRecon. When working as a plugin for those dense reconstruction baselines such as NeuS and Neuralangelo, the average error on the DTU dataset can be reduced by 69% and 68% respectively.
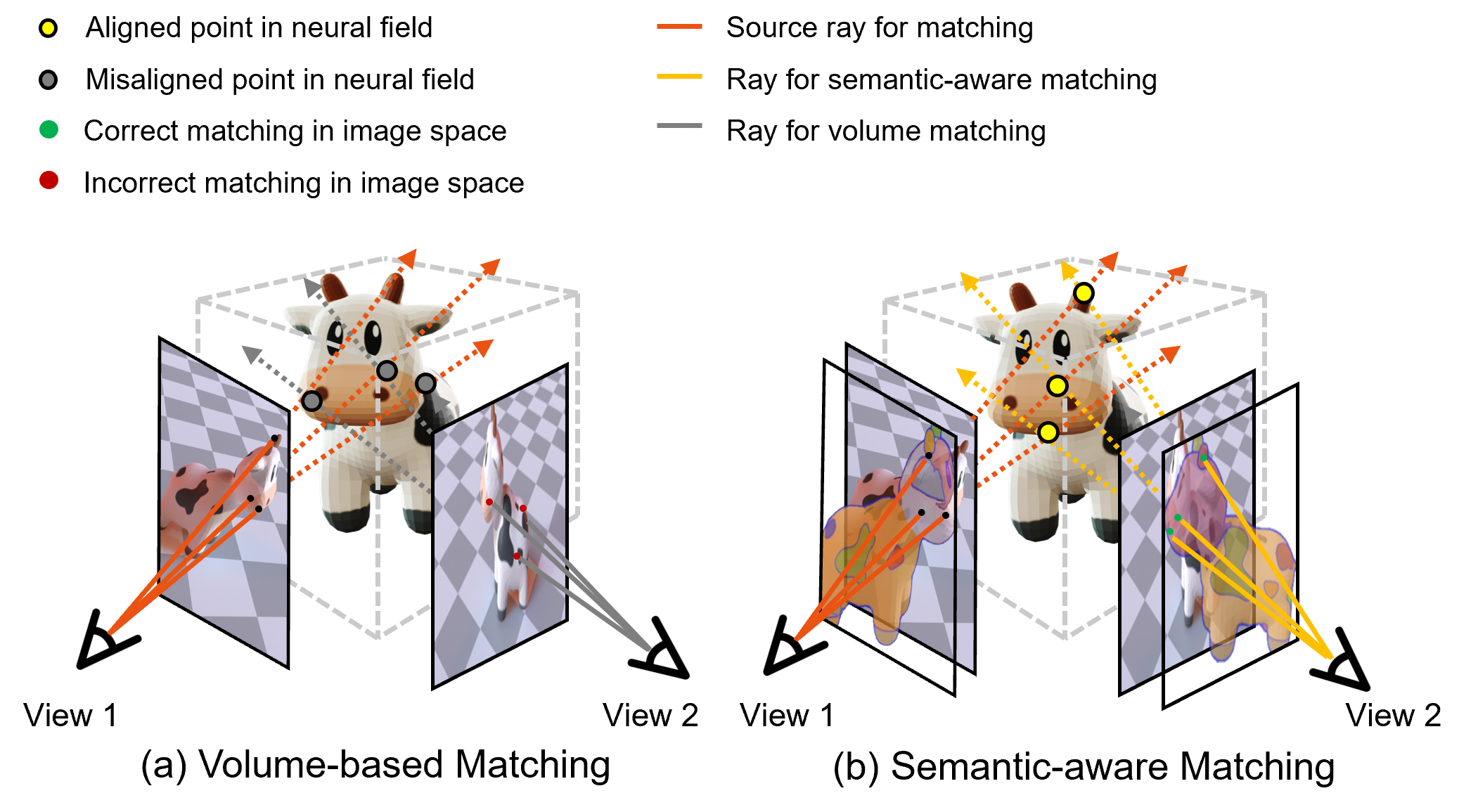
The basic idea of SERES is that computing a neural field from sparse input views for 3D reconstruction, incorrect matching is a major source of unsuccessful reconstruction. By incorporating semantic priors that are visualized as the masks of color patches on an additional layer, more correct matches can be obtained and this will significantly improved the quality of reconstruction.
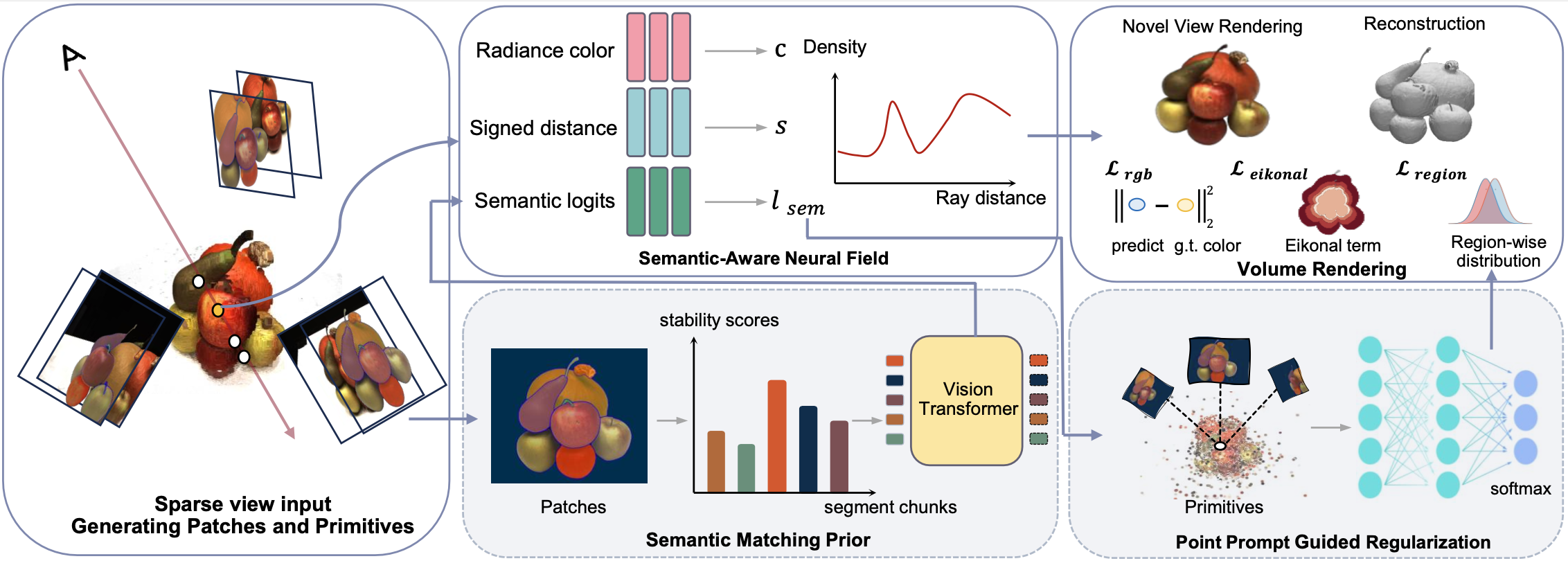
The overall pipeline of SERES encompasses the capability to reconstruct high-quality geometric meshes from sparse view input. We generate patches and primitives from sparse input and construct a semantic-aware neural field. The semantic matching prior for patches and the point prompt guided regularization are the fundamental components of the semantic-aware neural field. We optimize the learning of the neural field by incorporating the RGB loss obtained from volume rendering, along with the eikonal loss and the region loss obtained from point prompt-guided regularization.

Results of reconstruction for models in the DTU benchmark from 3 sparse views (as shown in the first column). The reconstruction results of prior methods are plagued by either geometric distortions (pixelNeRF and MVSNeRF ) or the loss of structural integrity (SparseNeuS and VolRecon ). Our SERES can reconstruct much more complete geometry with details.

Our SERES pipeline demonstrates superior performance in reconstructing models from the challenging BlendedMVS dataset using only 3 sparse views as shown in the first column. Unlike prior methods that often result in incomplete structures with holes, our approach can reconstruct more complete geometry with details

Experimental tests of our SERES as plugins to improve both the Neus and the Neuralangelo baselines, where the owl model is reconstructed from 3 views. It can be observed that the quality of both the reconstructed geometry and the images obtained from novel view synthesis has been significantly improved to approach the ground truth

Ablation study to explain the functionality of each module of our SERES pipeline, where ‘W/o Semantic’ and ‘Fixed Semantic’ refer to the results without incorporating semantic priors vs giving a fixed semantic matching prior (i.e., without optimization). The results of ‘W/o Point-prompt’ vs ‘Full’ demonstrate that our point-prompt guided regularization effectively mitigates mesh noise and reduces shape ambiguity. The values of chamfer distance (CD) are also given for each results
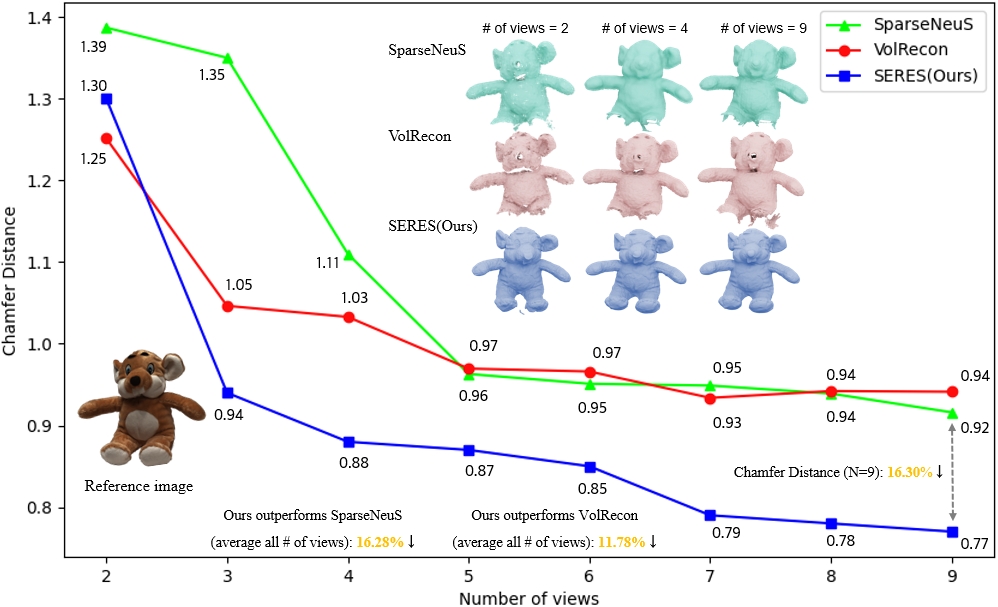
This study demonstrates that using more number of views, ranging from 2 to 9, can reduce up to 40.8% of the chamfer distances on the results of reconstruction. As can be found from the zoom-views, more input views are helpful to address radiance-ambiguity therefore contribute to the reconstruction of nuanced disparities.

Our SERES was deployed in four highly challenging in the wild scenes to investigate its performance. These scenes exhibit the following characteristics: high reflection, complex structure, intricate topology, and lack of texture. Even in these scenes with sparse input, SERES is capable of reconstructing geometric structures that are approximately accurate.